We strive for 100% uptime for all of our hosted software customers, but we’re not perfect. For starters, to keep our servers up-to-date, we do scheduled reboots about once/month, during off hours on the weekend, which results in about a minute of downtime (at least that’s what we do currently – we’re constantly improving our processes, so details like this can change any day). In the last decade of hosting, we’ve also experienced three server incidents that caused downtime for many of our customers – the last one happened a bit more than a year ago on a Saturday. The worst one happened in January 2010 and affected all of our users for 52 minutes (of hell). The fact is, nobody’s perfect (for more proof, watch my friend Tyler’s short talk on some amazing downtime events at Amazon – one of the best IT organizations in the world). Like any IT shop, we do a lot of proactive work to prevent incidents from happening – but when they do, we learn from the experience and take steps to ensure that the same type of event never happens again. Over the course of our hosting history, we’ve established between 99.95% and 99.99% (“four nines”) server uptime, and we’re continuously working to take that to the next level.
We’ve had other kinds of “non-downtime incidents” that affected a small number of our customers – of course, that’s no comfort if it affected you. For example, earlier this year, we made a change that made JobTracker unusable for anyone using Internet Explorer 8. That experience led us to make two changes. First, we added a status page as a way to report operational issues to our customers, both during and after a crisis. Second, we reviewed some of our testing and support processes – this particular issue ultimately only affected users who were running Windows XP … and since Microsoft is no longer supporting Windows XP, we can’t reasonably support it either. (Reminder: if you’re using Windows XP, you need to upgrade.)
If ever you tell us that you can’t get into Moraware, whether JobTracker or CounterGo, the first thing we do is go to your database URL ourselves (yourcompany.moraware.net). If we can’t get to the login page either, then that would be a pretty clear indication that the server needs attention. This is an “all hands on deck” scenario … pagers go off and people get rousted from bed if necessary. In fact, we use an automated service that continuously monitors our servers, so if they do ever go down, there’s a good chance we’d know about it before you do.
A couple of times each year, we hear from a handful of users that they can’t get to Moraware, yet we can still get to their login page – therefore, we know their server is up … on the other hand, they can still get to Google, so they know their Internet is working … how is this possible? To explain this particular type of issue, I need to provide quite a bit of geeky context.
The Internet is a pretty amazing invention – instead of requiring a direct connection between two computers, the Internet enables two computers (such as your desk and one of our servers) to communicate with each other through a complex web of routers. Your computer creates a connection with a little box (router) in your server closet, which communicates with a bigger router at your Internet Service Provider (ISP), such as Comcast or AT&T, which communicates with routers at other ISPs until a path is found to our Michigan-based data center, which connects to a router in one of our server racks, which communicates with the server where your database is running. Every time you click a button in our software, there can easily be 10-20 “hops” between your computer and our servers.
The Internet was also designed to be resilient, so if any one router goes down, another path to a desired destination can usually be found (unless it’s your router – then you won’t have any connection to the Internet at all). However, every now and then (2-4 times per year in our experience), an important router – perhaps at a significant ISP – goes down, and a handful of our customers can’t get to their Moraware databases. Usually, such an issue resolves itself in 10-15 minutes, because any significant ISP works hard to keep all of its connections working and to fix any problems as quickly as possible.
Unless such an issue resolves itself before we can talk with you, the first thing we would do is ask if you can access Moraware from your cellphone. Then, we might ask you to do a trace route, as follows:
- If necessary and possible, share your desktop and let us take control
- Open a command prompt (Windows start menu >> run >> cmd)
- Type tracert yourcompany.moraware.net
- Send us a screenshot (Alt-PrtSc and then Ctrl-V paste into an email)
When the routers between your desktop and our servers are working, a tracert looks something like this:
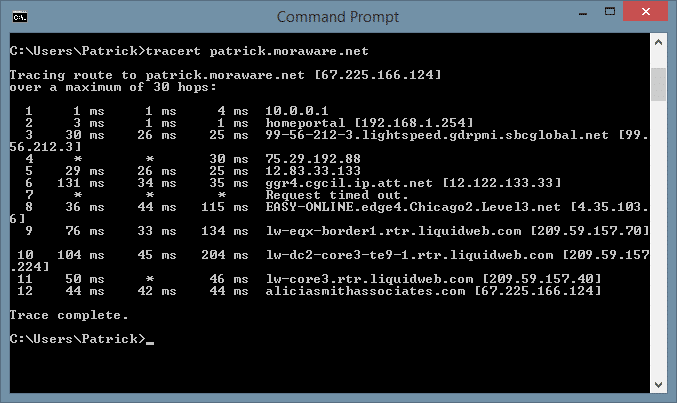
… or for readability, like this:
Tracing route to patrick.moraware.net [67.225.166.124] over a maximum of 30 hops: 1 1 ms 1 ms 4 ms 10.0.0.1 2 3 ms 1 ms 1 ms homeportal [192.168.1.254] 3 30 ms 26 ms 25 ms 99-56-212-3.lightspeed.gdrpmi.sbcglobal.net [99.56.212.3] 4 * * 30 ms 75.29.192.88 5 29 ms 26 ms 25 ms 12.83.33.133 6 131 ms 34 ms 35 ms ggr4.cgcil.ip.att.net [12.122.133.33] 7 * * * Request timed out. 8 36 ms 44 ms 115 ms EASY-ONLINE.edge4.Chicago2.Level3.net [4.35.103.6] 9 76 ms 33 ms 134 ms lw-eqx-border1.rtr.liquidweb.com [209.59.157.70] 10 104 ms 45 ms 204 ms lw-dc2-core3-te9-1.rtr.liquidweb.com [209.59.157.224] 11 50 ms * 46 ms lw-core3.rtr.liquidweb.com [209.59.157.40] 12 44 ms 42 ms 44 ms aliciasmithassociates.com [67.225.166.124] Trace complete.
Sometimes we’ll use tracert in the other direction as well. For example, here’s a tracert that failed from our servers to a customer in Montreal a while back:
Tracing route to (customer IP address) over a maximum of 30 hops 1 <1 ms <1 ms <1 ms lw-dc2-dist3-vlan195.rtr.liquidweb.com [67.225.166.2] 2 <1 ms <1 ms <1 ms 209.59.157.43 3 8 ms 8 ms 8 ms lw-border1.rtr.liquidweb.com [209.59.157.205] 4 7 ms 7 ms 7 ms lw-border1.rtr.liquidweb.com [209.59.157.1] 5 8 ms 8 ms 8 ms xe-8-1-2.edge2.Chicago2.Level3.net [4.35.97.61] 6 29 ms 29 ms 29 ms vl-3502-ve-116.ebr1.Chicago2.Level3.net [4.69.158.6] 7 29 ms 29 ms 29 ms ae-6-6.ebr1.Chicago1.Level3.net [4.69.140.189] 8 29 ms 29 ms 29 ms ae-10-10.car2.Montreal2.Level3.net [4.69.153.86] 9 * * * Request timed out. 10 * * * Request timed out. 11 * * * Request timed out. 12 * * * Request timed out. 13 * * * Request timed out. 14 * * * Request timed out.
This told us that there was something seriously wrong in Montreal – with a router neither of us had any control over – preventing us from getting to our customer or vice versa. It resolved itself within a few minutes.
Ah, but what about the fact that you can still reach Google or Bing or Yahoo or Amazon or some other popular website? These web companies don’t have “a few servers” – they have many thousands of servers in multiple data centers placed strategically throughout the globe. If you can’t reach the “default” server for your location because of some network anomaly, the Internet will essentially try the next closest one until it finds one that works (that’s a gross oversimplification, but you get the general idea).
While we’ll never have as many data centers as the big sites mentioned above, we’re working to have more than just the one we currently have. Our customers depend on our software, and we want to do everything we possibly can to make sure you can always reach your data. Unfortunately, making software work seamlessly across multiple locations so that you would never know or care if a router went down somewhere between your desktop and our servers … well, it’s hard. We’re pointed in that direction, but we have to make some surprisingly significant changes to make everything work. It’s going to take us at least another year before this is implemented. In the meantime, most of our customers will never experience the kind of router problem described above, but if you do – and if it doesn’t resolve itself quickly – we’ll take whatever measures are possible to help you keep your business running. For example, we’ll email you reports or files – or if possible, we’ll share our desktop with you so that you can access your data from our location.
There are also proactive steps that you can take to help ensure that your own network is healthy, so that you can always get to your Moraware software. First and foremost, use a high-quality Internet provider. From time to time, check your speed at a site like https://www.speedtest.net (be sure to click on the map and not an ad) to see if you’re getting close to what you’re paying for. If your measured speed is 80% of what your ISP publishes, that’s probably fine – if it’s 20%, that’s probably not – and note that downstream speed is often ten times faster than upstream. If your Internet goes down frequently, switch to a competitor. Or better yet, get a “load balancing router,” and use two Internet providers simultaneously (I’ll write more about this technique in a future post). Consider having a backup source of Internet like a wireless hotspot from your mobile provider that you can use from a laptop if your main Internet goes down.
There are even lower tech precautions … many of our customers have a staging process where project files are downloaded from Moraware into their equipment – and many have learned to download those files to the local machine at least one job (or one day) ahead, just in case they have network issues – the most important thing is to make sure your shop doesn’t shut down. And while some of our customers run a paperless office, others prefer to print key forms, views, and/or reports each day – again, just in case.
In the end, the only reason our software matters is if it helps you run your business. We’re working hard to minimize any disruptions and to make sure that it “just works” so that you can focus on more important things. As always, if there is ever a problem, don’t hesitate to reach out to us at support@moraware.com or 866-312-9273.